Tout à mes réflexions concernant un programme me permettant de déterminer mes origines, je me rends compte que j'ai omis la prise en compte des implexes ! Dans mon précédent billet, j'écrivais :
De manière évidente le coefficient de pondération lié à un individu est identique à tous les individus d'une génération donnée, et nous donne
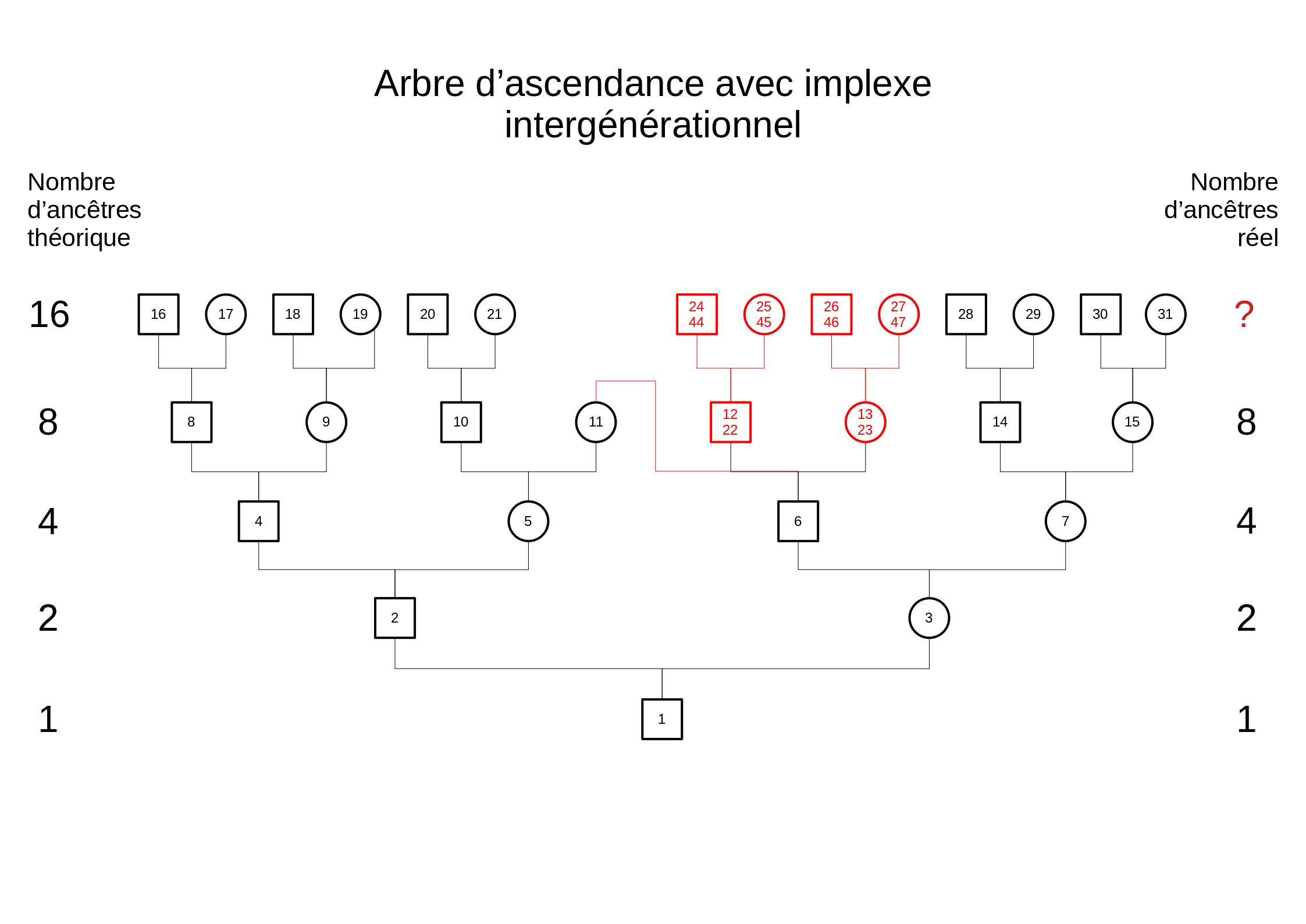
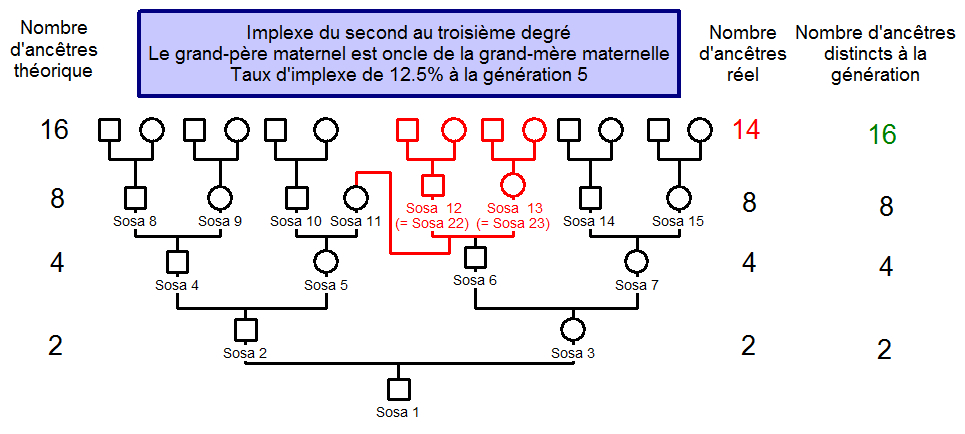
Ah, bah oui... mais nan ! Si la génération ne compte pas individus mais un nombre indéterminé , le coefficient devrait être . Simple ! Oui... mais non. En effet comment prendre en compte les implexes intergénérationnels ? Prenons l'exemple donné sur la page Wikipédia :
Implexe du second au troisième degré
Source : Wikipédia
Dans l'exemple ci-contre d'implexe du second au troisième degré (le grand-père maternel étant oncle de la grand-mère maternelle), le même couple apparaît comme unique (portant à la fois les numéros Sosas 12-13 et 22-23) à deux générations distinctes. La formule de base donne bien un taux d'implexe de 12,5 % ((16-14)/16) à la cinquième génération, mais sur base de la nouvelle formule (rapport ancêtres distincts/ancêtres trouvés), le taux d'implexe devient 0 %, les ancêtres communs aux générations 4 et 5 étant considérés comme distincts.
Du coup, comment calculer le taux d'implexe ? Cet exemple montre que la notion de génération est une construction de l'esprit et que rien ne nous empêche de modifier notre conception "d'individu appartenant à une génération"... Pourquoi ne pas considérer des demi individus par exemple ? Une personne apparaissant dans deux générations différentes compterait pour un demi individu dans chaque génération. Sur le plan de la modélisation, cela revient à considérer l'ascendance comme un graphe non orienté, connexe et acyclique (c'est à dire un arbre mathématique), dans lequel les implexes et leurs ascendants apparaissent autant de fois que nécessaire et a donner un poids à chaque individu de , étant le nombre de fois que l'individu apparaît dans l'arbre. Appelons ce modèle Arbre à Individus Partiels (AIP) pour facilité la compréhension.
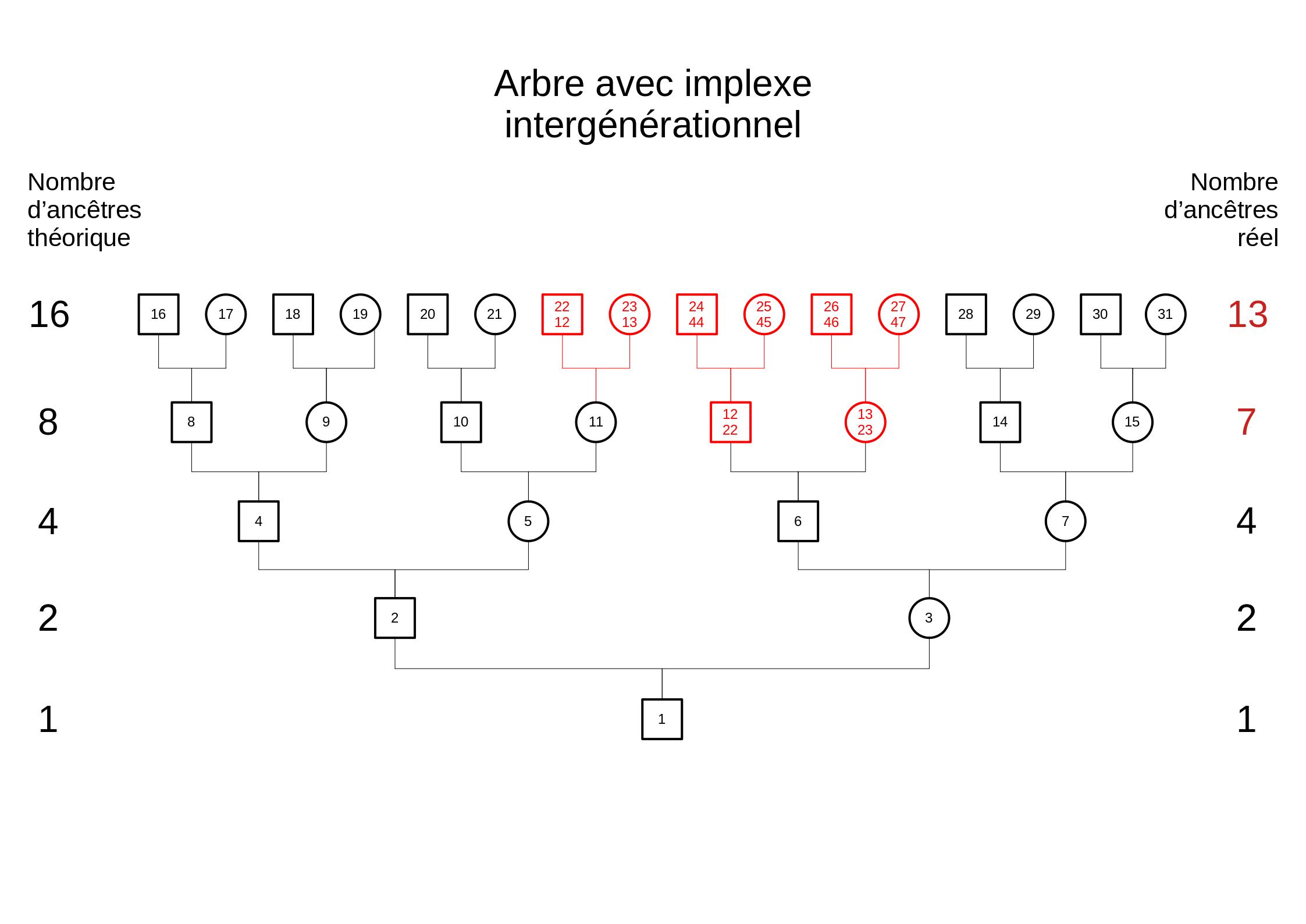
Cela ne modifie rien pour les implexes intragénérationnels, chaque individu apparaissant deux fois ayant un poids total de 1. Par contre cela résoud le problème des implexes intergénérationnels. Considérons l'ascendance telle qu'on la représente traditionnellement et son équivalent AIP :
Ascendance avec implexe intergénérationnelAIP avec implexe intergénérationnel
Ce modèle AIP permet de calculer un taux d'implexe de 18.75% ((16 - 13) / 16) à partir de la génération 5 et ce taux reste identique ensuite, comme attendu.
Pour revenir au problème initial, il est possible de prendre en compte les implexes, même intergénérationnels, dans les calculs que j'envisage pour déteriner mes origines. Cela est-il souhaitable pour autant ? Et c'est là qu'entre en jeu le complexe de l'implexe ! Pour une personne présente deux fois dans mon arbre (mon sosa 32 qui est aussi mon sosa 38) doit-il compter pour 1 ou pour 2 ? S'il avait transmis un héritage équitablement réparti à sa descendance, j'en aurai obtenue double ration (par rapport à la situation où il ne serait pas un implexe) et il faudrait le compter pour 2 ! D'un autre côté, les hommes naissent et demeurent libres et égaux en droits et mon sentiment égalitaire s'oppose à compter une personne comme deux fois plus importante qu'une autre... Surtout que je n'ai pas particulièrement envie que certains comptent double !
En commençant ma généalogie, je me suis vite aperçu que mes ancêtres paternels venaient essentiellement du poitou alors que je nous croyais nantais avant tout ! En remontant dans les générations, des ancêtres d'autres régions apparaissent, déclenchant chez moi un nouvel intérêt pour ces lieux qui m'étaient auparavent indifférents. C'est ainsi que j'ai commencé à me poser la question de mes origines géographiques. D'où viennent mes ancêtres et comment quantifier la part de chaque lieu dans mon identité ? Bien sûr, l'identité est avant tout une construction psychologique et sociale, mais la généalogie et la découverte de la provenance géographique de ses ancêtres procède justement de cette construction. Par exemple, me découvrant un ancêtre de Seine-Maritime, je me sens maintenant un peu normand !
D'autres se sont penchés sur la question, comme Rémi Costantino sur ingénéalogie qui présente une réflexion profonde sur le sujet en deux parties (partie I, partie 2). Cependant, Je trouve la méthode beaucoup trop complexe et ne répondant pas complètement à ma définition des origines.
Beaucoup se pose la question de savoir si c'est le lieu de naissance ou le lieu où la personne à le plus vécue qu'il faut prendre en compte. Je pense que cette question perd de sa pertinance quand on constate que rare sont nos ancêtres à être nés à un endroit et à avoir vécu à un autre très éloigné (les grandes migrations sont rares avant la fin du XIXe siècle). Et quand bien même, les parents de cet ancêtre ont toutes les chances d'être nés et d'avoir vécu au lieu de naissance de leur enfant. Ainsi même s'il n'a pas vécu à un endroit, il en a surement l'identité. Par exemple, ma femme, née en Auvergne, est fille de réfugiés espagnols et se sens autant auvergnate qu'espagnole !
Je propose donc de définir les origines géographiques d'une personne comme une somme pondérée des lieux de naissance des individus de son arbre d'ascendance, la personne considérée inclue. Cette pondération tient compte de la génération de l'individu (plus la génération est ancienne, moins elle pèse dans la somme) et du nombre d'individus dans la génération.
Tentons de modéliser mathématiquement le problème. Commençons par poser les définitions suivantes :
, la génération de rang , ( étant la personne considérée et étant le rang de la génération la plus ancienne)
, le coefficient de pondération lié à la génération de rang ,
, le coefficient de pondération lié à l'individu , né dans le lieu de la génération de rang ,
, le poids du lieu dans les origines géographiques de la personne représentée par la génération
Le poids du lieu dans les origines géographiques de la personne représentée par la génération est le poids que l'on cherche à calculer pour chaque lieu de naissance des individus de l'arbre :
De manière évidente le coefficient de pondération lié à un individu est identique à tous les individus d'une génération donnée, et nous donne
Comment choisir ? Autrement dit, pour combien contribue la génération de rang dans le calcul de ? Une première approche est de se dire que le poids d'une génération décroit de manière linéaire de quand à quand , à savoir . Afin de normaliser le résultat, il convient d'avoir une somme de tous les individus sur toutes les générations égale à , permettant ainsi la comparaison entre personnes. Or, . Par conséquent :
Le problème avec cette approche linéaire est que le poids d'une génération dépend du nombre de générations prises en compte . La comparaison entre deux individus ne peut donc se faire qu'au même niveau de génération, sans quoi cela ne veut plus rien dire. Ensuite, à mon avis, cette fonction linéaire ne donne pas assez de poids aux premières générations qui ont vraiment un sens pour nous (lieu de naissance de nos parents et grands parents, voire arrières grands parents) par rapport aux générations précédentes.
C'est pourquoi, je propose d'utiliser une suite géométrique convergeante de raison qui permet à la fois de donner plus de poids aux premières générations et de normaliser le résultat quelque soit le nombre de générations puisque l'on somme sur un nombre infini de génération (). De plus, la part de lieux d'origine inconnue est prise en compte ! Comme , on obtient :
Il reste alors à déterminer une valeur pour . Je propose de la calculer telle que les 4 premières générations compte pour 75% de la totalité, à savoir :
Ce qui donne :
Yapuka écrire un petit programme pour faire ça et produire des cartes et graphiques pour illustrer sa généalogie !
J'avais réalisé Casimir, une distribution libre des cartes de Cassini, c'est à dire que chacun est libre d'en faire des copies, et de les distribuer, initialement disponible uniquement sur CD. Après l'avoir distribuée à près d'une centaine de personnes, et les capacités de stockage de mon hébergeur me le permettant, elles sont disponibles en ligne, en noir et blanc et en couleur.
Il existe déjà, sur Internet, des sites excellents et incontournables permettant, entre autre de visualiser, de naviguer et de télécharger les cartes de Cassini :
Cependant, tous s'appuient sur les images libres de droit, mises à la disposition par le site Gallica. Cela présente deux inconvéniants :
le morcellement de chaque carte en 676 images (interdisant l'utilisation de portion de carte dépassant les limites d'une image pour qui ne connaît pas la technique d'assemblage des images),
le temps de (télé-)chargement&nnbsp;: 676 requêtes HTTP pour télécharger les 676 images constituant chaque carte.
J'ai donc réalisé le téléchargement des 676 images de toutes les cartes et procédé à leur assemblage automatique (à l'aide du logiciel libre ImageMagick). Ce travail effectué, je souhaite maintenant en faire profiter tout le monde.
Chaque carte est une image au format jpeg de 1 à 10 Mo. Toutes les cartes en noir et blanc disponibles sur Gallica ont été réalisées ; 13 cartes ne sont disponibles qu'en couleur.
{kind=link}